Into the INFERNO: parameter estimation under uncertainty - Part 5
In this series of posts, we'll be looking at one of the most common problems in high-energy physics; that of estimating some parameter of interest. In this concluding post we'll examine one of the concerns raised in the last post about having to know the analytical effect of nuisance parameters on input features and see how we can instead approximate the effects.



Welcome back to the concluding part of this blog-post series. In case you missed the previous posts: first, second, third, and fourth.
Last time we applied INFERNO to the toy-example presented in the INFERNO paper, and demonstrated how the method made our parameter estimation more resilient to the effects of nuisance parameters that affect both the shapes of input features and the overall normalisation of the classes. Here we'll look at how we can achieve the same effect without having to know the analytical effect of the nuisance parameters on the input features.
As a reminder, we're using a PyTorch implementation of INFERNO which I've put together. The package can be installed using:
!pip install pytorch_inferno==0.0.1
Docs are located here and the Github repo is here. I'm installing v0.0.1 here, since it was what I used when writing this post, but for your own work, you should grab the latest version.
As an additional note, these blog posts are fully runnable as Jupyter notebooks. You can either download them, or click the Google Colab badge at the top to follow along!
The approach as presented last time, requires modelling the effect of the shape nuisances on the inputs in an analytical manner. Usually, though, this is difficult. As an example, in high-energy physics, we often have systematic uncertainties like QCD scale, various energy scales, and correction factors for upstream algorithms. These affect a range of features of the data in complex ways. Additionally, their effects are sometimes modelled by changing fundamental parameters in the Monte Carlo simulator used to generate training data.
Knowing exactly how variations in a given nuisance parameter alter the input features is not normally possible. Indeed, when we have optimised the likelihood in previous posts, we have assumed this and so haven't fully propagated the effects of the parameters through our classifier, instead we generated up/down systematic variations for the model response and interpolated between them and the nominal template (or extrapolated away from them). The trick, then, is to also do this interpolation/extrapolation inside INFERNO.
When performing a HEP analysis with systematic uncertainties, these up/down variation samples are usually generated via modifying the relevant parameters in the simulation, i.e. for an analysis one has a nominal dataset and also datasets for up and down variations for each nuisance parameter separately. The approximation of INFERNO presented here is designed to work directly on such datasets.
One key point is that we will compare nominal and systematic datasets in terms of template shape, rather than on a per data-point level. This means that the systematic datasets don't have to match the nominal dataset event-wise, i.e. we don't need to know how a given event would change if a certain parameter were altered, instead we only need to know the average effect that changing the parameter causes. This certainly simplifies things from both a simulation and implementation point of view.
The interpolation-based INFERNO loss in pytorch_inferno is implemented similar to the exact version, i.e. as a callback. Again, there is an abstract class implementing the basic functionality, and the idea is that users can inherit from it to apply to their specific problems, e.g in our case PaperInferno. Note however that even the "abstract" class is still designed for a Poisson counting problem.
Let's go through the code function by function:
def __init__(self, n:int, true_mu:float, aug_alpha:bool=False, n_alphas:int=0, n_steps:int=100, lr:float=0.1,
float_b:bool=False, alpha_aux:Optional[List[Distribution]]=None, b_aux:Optional[Distribution]=None):
super().__init__()
store_attr()
self.true_b = self.n-self.true_mu
The initialisation is similar to the exact version: Asimov count n, and the true signal strength true_mu. The true background count is then computed automatically. n_alphas is the number of shape systematics to expect and float_b is whether or not the background normalisation should be allowed to vary. Any auxiliary measurements for the shape parameters and background yield can be passed as PyTorch distributions to the alpha_aux and b_aux arguments.
There is also the option to augment the nuisance parameters aug_alpha. This is an idea I had which is still experimental - basically the nuisances start each minibatch at random points about their nominal values and undergo Newtonian optimisation according to lr and n_steps. This could perhaps be thought of as a form of regularisation or data-augmentation. In this example it seems to work well, but as I say, it's still experimental, so I won't talk about it much here.
def on_train_begin(self) -> None:
self.wrapper.loss_func = None
for c in self.wrapper.cbs:
if hasattr(c, 'loss_is_meaned'): c.loss_is_meaned = False
Unlike the exact version, when the training starts we don't need to cache a tensor of the nuisance parameters, but we do still want to ensure that the model doesn't have any other losses.
Having passed the nominal input data through the network, we call:
def on_forwards_end(self) -> None:
r'''Compute loss and replace wrapper loss value'''
b = self.wrapper.y.squeeze() == 0
f_s = self.to_shape(self.wrapper.y_pred[~b])
f_b = self.to_shape(self.wrapper.y_pred[b])
f_b_up,f_b_dw = self._get_up_down(self.wrapper.x[b])
self.wrapper.loss_val = self.get_ikk(f_s=f_s, f_b_nom=f_b, f_b_up=f_b_up, f_b_dw=f_b_dw)
This extracts the normalised shapes for signal and background (their PDFs) from the network predictions (self.wrapper.y_pred). Unlike the exact version, the background predictions don't include the shape nuisances. In order to evaluate these, we pass the background data to self._get_up_down, which passes up/down systematic data through the network and returns the shape templates. Currently it an abstract function to be overridden in a problem-specific class.
@abstractmethod
def _get_up_down(self, x:Tensor) -> Tuple[Tensor,Tensor]:
r'''Compute up/down shapes. Override this for specific problem.'''
pass
Now that we have nominal shape templates for signal and background, and the shape templates for background after +1 and -1 sigma variations of each shape-affecting nuisance parameters, we are now at a similar state to when we are evaluating the trained models on the benchmark problems in the previous posts. I.e. we can compute the negative log-likelihood, and optimise it by varying the nuisance parameters based on interpolating between the nominal and ±1-sigma variations, for fixed values of the parameter of interest.
The key point is that we actually start with the nuisances at their nominal values, and we only need to evaluate the parameter of interest at its nominal value, so no optimisation is required. The actual implementation includes code for applying the data augmentation mentioned earlier, but I'll remove it here for simplicity.
def get_ikk(self, f_s:Tensor, f_b_nom:Tensor, f_b_up:Tensor, f_b_dw:Tensor) -> Tensor:
r'''Compute full hessian at true param values, or at random starting values with Newton updates'''
alpha = torch.zeros((self.n_alphas+1+self.float_b), requires_grad=True, device=self.wrapper.device)
with torch.no_grad(): alpha[0] += self.true_mu
get_nll = partialler(calc_nll, s_true=self.true_mu, b_true=self.true_b,
f_s=f_s, f_b_nom=f_b_nom, f_b_up=f_b_up, f_b_dw=f_b_dw, alpha_aux=self.alpha_aux, b_aux=self.b_aux)
nll = get_nll(s_exp=alpha[0], b_exp=self.true_b+alpha[1] if self.float_b else self.true_b, alpha=alpha[1+self.float_b:])
_,h = calc_grad_hesse(nll, alpha, create_graph=True)
return torch.inverse(h)[0,0]
So, first we create a tensor, alpha, to contain the parameter of interest and the nuisance parameters (all zero except the parameter of interest (PoI)), and then we compute the NLL using calc_nll (we've called this function in the past when evaluating benchmarks, but it has been wrapped by calc_profile to handle multiple PoIs). Once we have the NLL, we can then compute the INFERNO loss as usual by inverting the Hessian of the NLL w.r.t. the PoI and nuisances (calc_grad_hesse), and returning the element corresponding to the PoI.
Similar to last time, we want to inherit from our abstract implementation of INFERNO to better suit the problem at hand. PaperInferno is included to work with the toy problem in the original paper. I mentioned at the start that this approximation of INFERNO was designed to work with pre-produced datasets that contain both nominal and systematic datasets, however for this example, we'll generate the systematic datasets on the fly since we can analytically modify the inputs. If we were to do this properly, we would generate the systematic datasets beforehand, and allow the callback to sample batches from them during training. Probably I'll eventually add a class to the library that can do this.
Anyway, for now, our class overrides _get_up_down like this:
def _get_up_down(self, x:Tensor) -> Tuple[Tensor,Tensor]:
if self.r_mods is None and self.l_mods is None: return None,None
u,d = [],[]
if self.r_mods is not None:
with torch.no_grad(): x = x+self.r_mod_t[0]
d.append(self.to_shape(self.wrapper.model(x)))
with torch.no_grad(): x = x+self.r_mod_t[1]-self.r_mod_t[0]
u.append(self.to_shape(self.wrapper.model(x)))
with torch.no_grad(): x = x-self.r_mod_t[1]
if self.l_mods is not None:
with torch.no_grad(): x = x*self.l_mod_t[0]
d.append(self.to_shape(self.wrapper.model(x)))
with torch.no_grad(): x = x*self.l_mod_t[1]/self.l_mod_t[0]
u.append(self.to_shape(self.wrapper.model(x)))
with torch.no_grad(): x = x/self.l_mod_t[1]
return torch.stack(u),torch.stack(d)
I.e. it modifies the current data, passes it through the model, and constructs the templates for independent up and down systematics. A proper implementation would instead sample minibatch x from the respective systematic dataset and pass it through the model
We train the network in a similar fashion as in part-4, except we now use the approximated version of INFERNO
from pytorch_inferno.utils import init_net
from pytorch_inferno.model_wrapper import ModelWrapper
from torch import nn
def get_model() -> ModelWrapper:
net = nn.Sequential(nn.Linear(3,100), nn.ReLU(),
nn.Linear(100,100),nn.ReLU(),
nn.Linear(100,10), VariableSoftmax(0.1))
init_net(net) # Initialise weights and biases
return ModelWrapper(net)
from pytorch_inferno.data import get_paper_data
data, test = get_paper_data(n=200000, bs=2000, n_test=1000000)
from pytorch_inferno.inferno_interp import PaperInferno, VariableSoftmax
from torch import distributions
inferno = PaperInferno(r_mods=(-0.2,0.2), # Let r be a shape nuisance and specify down/up values
l_mods=(2.5,3.5), # Let lambda be a shape nuisance and specify down/up values
float_b=True, # Let the background yield be a nusiance
alpha_aux=[distributions.Normal(0,2), distributions.Normal(0,2)], # Include auxiliary measurements on r & lambda
b_aux=distributions.Normal(1000,100)) # Include auxiliary measurements on the background yield
Now let's train the model. In contrast to the paper, we'll use ADAM for optimisation, at a slightly higher learning rate, to save time. We'll also avoid overtraining by saving when the model improves using callbacks. Note that we don't specify a loss argument.
from fastcore.all import partialler
from torch import optim
from pytorch_inferno.callback import LossTracker, SaveBest, EarlyStopping
model = get_model()
model.fit(200, data=data, opt=partialler(optim.Adam,lr=8e-5), loss=None,
cbs=[inferno,LossTracker(),SaveBest('weights/best_inferno.h5'),EarlyStopping(5)])
Having trained the model, we again want to bin the predictions via hard assignments
from pytorch_inferno.inferno import InfernoPred
preds = model._predict_dl(test, pred_cb=InfernoPred())
import pandas as pd
df = pd.DataFrame({'pred':preds.squeeze()})
df['gen_target'] = test.dataset.y
df.head()
from pytorch_inferno.plotting import plot_preds
import numpy as np
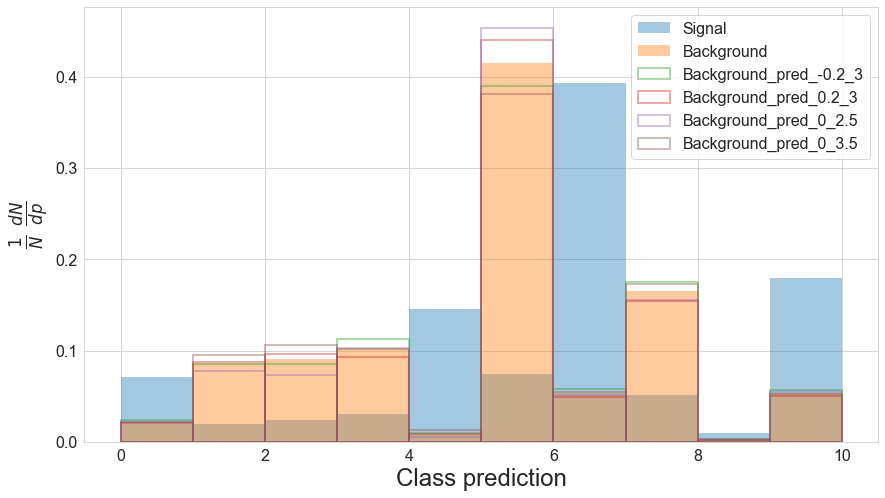
plot_preds(df, bin_edges=np.linspace(0,10,11))

To save time let's test the method on just the easiest and most difficult benchmarks. For readability, I'll hide the code cells (they'll still show up if you open the notebook yourself to run it).
from pytorch_inferno.plotting import plot_likelihood
plot_likelihood(nll-nll.min())

As a reminder, the binary cross-entropy classifier achieved a width of 15.02, and the exact version of INFERNO got 15.86, so the interpolation version does quite well!
%%capture --no-display
alpha_aux = [torch.distributions.Normal(0,2), torch.distributions.Normal(0,2)]
nll = profiler(alpha_aux=alpha_aux, float_b=True, b_aux=torch.distributions.Normal(1000,100), **b_shapes).cpu().detach()
plot_likelihood(nll-nll.min())

Again, the interpolation method does pretty well: the BCE classifier blew up to a width of 27.74, and the exact version of INFERNO got a much better constraint of 19.08 (slightly high compared to the paper value of 18.79).
In this post we've looked at how the INFERNO method can be implemented without requiring analytical knowledge of how the nuisance parameters affect the inputs in the data. Instead we have approximated their affects by interpolating between up/down systematics datasets about the the nominal values. Such datasets are already produced during the course of a typical HEP analysis, and so this approximation improves the potential to be a drop-in replacement for the event-level classifier used in contemporary analyses.
Whilst I've only tested the approximation using the same toy-data problem used by the paper, I have found that it was able to match the performance of the exact version, so I'll be interested to see how well it performs on real-world problems. Certainly, given the difference in performance illustrated by INFERNO (exact or interpolated) and a traditional BCE network, I think the method has a lot to offer in domains where uncertainties play a key role, and I'm looking forward to testing it out.